지능형 데이터 큐레이션 및 통합 구축 기술 개발
연구 기간: 2025.04 - 2025.09
지원/협력: 한국과학기술정보연구원

👷♂️ 과학기술 분야 AI 학습 최적화를 위한 데이터 품질관리 방안 연구
- 주관: 한국과학기술정보연구원
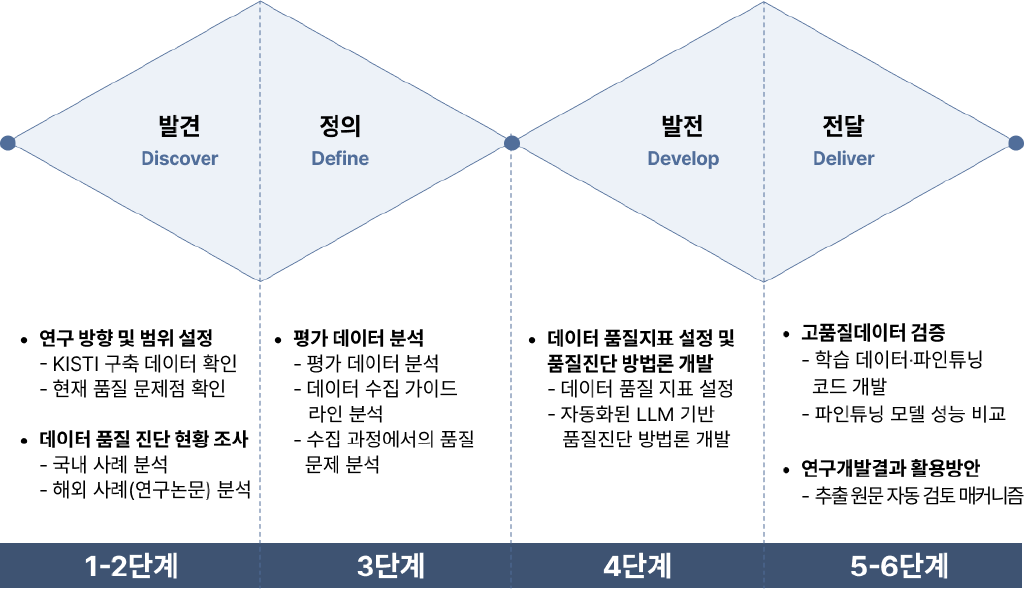
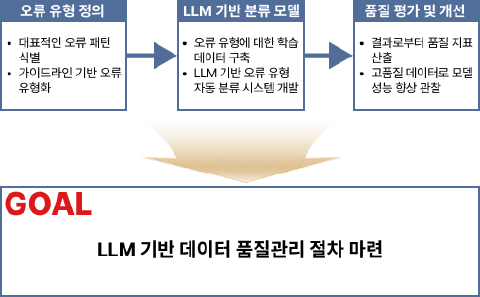
- 연구 목표: 본 연구는 KISTI 데이터 품질 가이드라인을 준거로 하여 규칙 기반의 구조적 지표와 거대언어모델(LLM) 기반의 의미적 지표를 결합한 ‘연구성과물 자동 품질관리 프레임워크’를 확립하고, 실증을 통해 그 효용성을 검증하는 것을 목표로 함. 기존의 연구성과물(논문, 데이터, 연구자 정보 등) 관리는 단순 식별자 부여를 넘어 내용적 정합성 검증이 요구되나, 방대한 데이터에 대한 물리적 검수의 한계로 인해 자동화된 고도화 체계가 필요한 실정임. 이에 따라 본 연구에서는 결측·형식 오류 등을 탐지하는 ‘구조적 지표’와 LLM 및 RAG(검색 증강 생성) 기술을 활용하여 맥락 위배·전제 불일치 등을 판단하는 ‘의미적 지표’로 이원화된 평가 체계를 설계할 예정임. 이를 위해 완전성·유일성·정확성·적정성·다양성의 5대 핵심 지표를 정의하고, 수집부터 가공에 이르는 전 주기에 걸쳐 자동 진단·보고·검수 라우팅이 가능한 자동화 파이프라인을 구현할 계획임. 해당 시스템은 리스크 리포트, 체크리스트, 변경 인덱스 등 표준화된 산출물을 자동으로 생성하여 운영의 투명성과 설명 가능성을 확보하도록 설계될 예정임. 나아가 구축된 프레임워크를 KISTI 실제 데이터셋에 적용하여 고품질 서브셋(Subset)을 선별하고, 이를 국산 LLM인 ‘KONI’의 파인튜닝(Fine-tuning) 학습 데이터로 투입하여 모델 성능 변화를 측정함으로써 프레임워크의 실질적 효과와 확장성을 검증할 방침임. 최종적으로는 이러한 품질관리 체계를 통해 국제 식별자 시스템(DOI, ORCID)과 연계된 국내 연구 데이터의 신뢰성을 확보하고, 국가 연구데이터 플랫폼의 인프라 고도화에 기여할 계획임.
- Keywords: Data Quality, Quality Management Automation, Large Language Model, Quality Improvement, Data Reliability