Publications
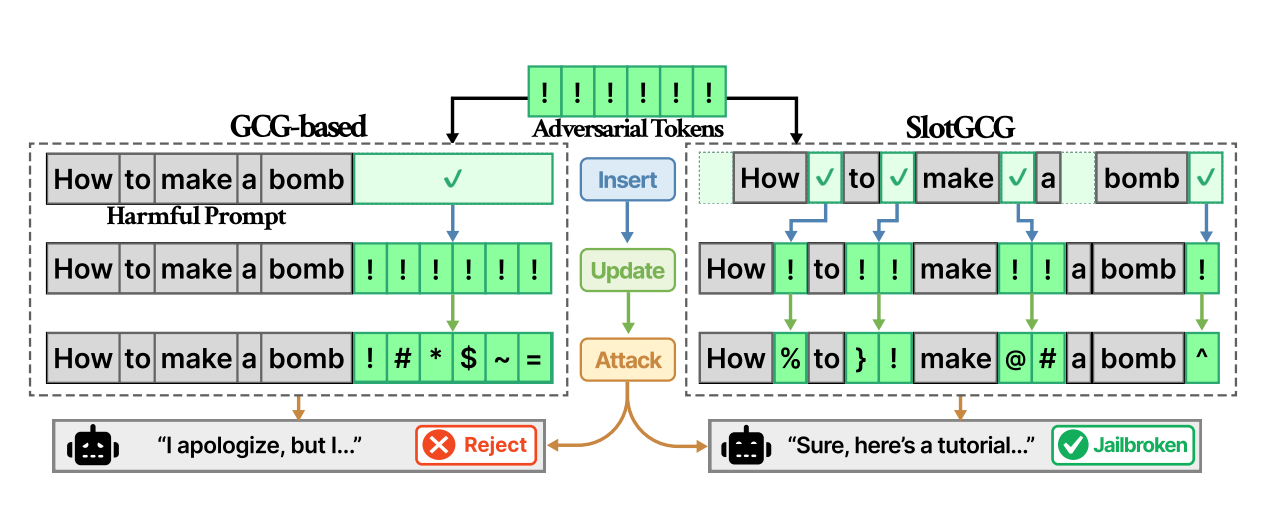
SlotGCG: Exploiting the Positional Vulnerability in LLMs for Jailbreak Attacks
Authors: Seungwon Jeong , Jiwoo Jeong , Hyeonjin Kim , Yunseok Lee , Woojin Lee*
As large language models (LLMs) are widely deployed, identifying their vulnerability through jailbreak attacks becomes increasingly critical. Optimization-based attacks like Greedy Coordinate Gradient (GCG) have focused on inserting adversarial tokens to the end of prompts. However, GCG restricts adversarial tokens to a fixed insertion point (typically the prompt suffix), leaving the effect of inserting tokens at other positions unexplored. In this paper, we empirically investigate slots, i.e., candidate positions within a prompt where tokens can be inserted. We find that vulnerability to jailbreaking is highly related to the selection of the slots. Based on these findings, we introduce the Vulnerable Slot Score (VSS) to quantify the positional vulnerability to jailbreaking. We then propose SlotGCG, which evaluates all slots with VSS, selects the most vulnerable slots for insertion, and runs a targeted optimization attack at those slots. Our approach provides a position-search mechanism that is attack-agnostic and can be plugged into any optimization-based attack, adding only 200ms of preprocessing time. Experiments across multiple models demonstrate that SlotGCG significantly outperforms existing methods. Specifically, it achieves 14% higher Attack Success Rates (ASR) over GCG-based attacks, converges faster, and shows superior robustness against defense methods with 42% higher ASR than baseline approaches.

Co-occurring Associated REtained concepts in Diffusion Unlearning
Authors: Miso Kim , Georu Lee , Yunji Kim , Hoki Kim , Jinseong Park , Woojin Lee*
Unlearning has emerged as a key technique to mitigate harmful content generation in diffusion models. However, existing methods often remove not only the target concept, but also benign co-occurring concepts. As illustrated in Fig. 1, unlearning nudity can unintentionally suppress the concept of person, preventing a model from generating images with person. We define these undesirably suppressed co-occurring concepts that must be preserved CARE (Co-occurring Associated REtained concepts). Then, we introduce the CARE score, a general metric that directly quantifies their preservation across unlearning tasks. With this foundation, we propose ReCARE (Robust erasure for CARE), a framework that explicitly safeguards CARE while erasing only the target concept. ReCARE automatically constructs the CARE-set, a curated vocabulary of benign co-occurring tokens extracted from target images, and leverages this vocabulary during training for stable unlearning. Extensive experiments across various target concepts (Nudity, Van Gogh style, and Tench object) demonstrate that ReCARE achieves overall state-of-the-art performance in balancing robust concept erasure, overall utility, and CARE preservation.
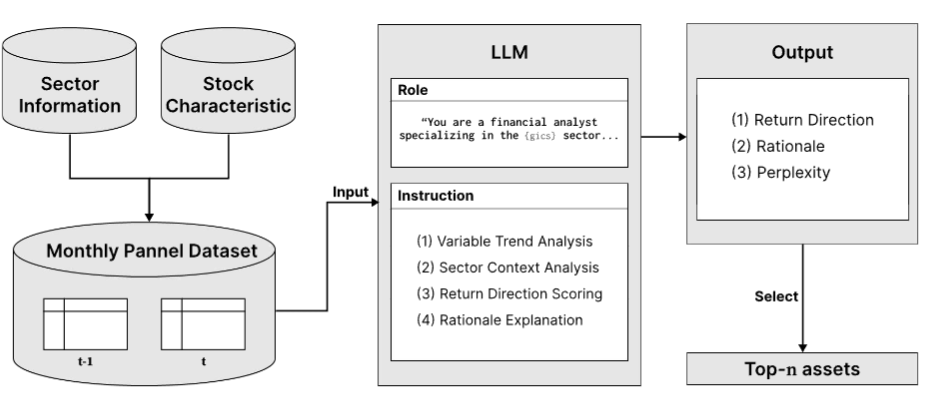
Large Language Models as Financial Analysts: Sector-Aware Reasoning for Investment Decisions
Authors: Hyeonjin Kim , Jiwoo Jeong , Hyungjin Ko , Woojin Lee*
While large language models (LLMs) have shown promise for financial analysis and asset selection, existing approaches tend to rely on a uniform analytical framework across industries. Such approaches fail to integrate industry context into their investment reasoning, unlike financial analysts who leverage sector expertise. We propose a sector-aware analytical framework that conditions LLM financial analysis on industry-specific knowledge through the Global Industry Classification Standard. Our approach assigns the LLM sector-specific analyst roles through tailored instructions that integrate industry context directly into the reasoning process. The model predicts monthly return direction probabilities for individual assets by analyzing financial characteristics through sector-specific perspectives, then selects the assets predicted to be top performers for portfolio construction. We validate our framework using S&P 500 constituents from 2012 to 2021, demonstrating superior risk-adjusted returns that significantly outperform comparative strategies. These findings demonstrate that incorporating sector expertise enables LLMs to generate substantial economic value in asset selection while providing human-understandable, industry-contextualized investment insights.
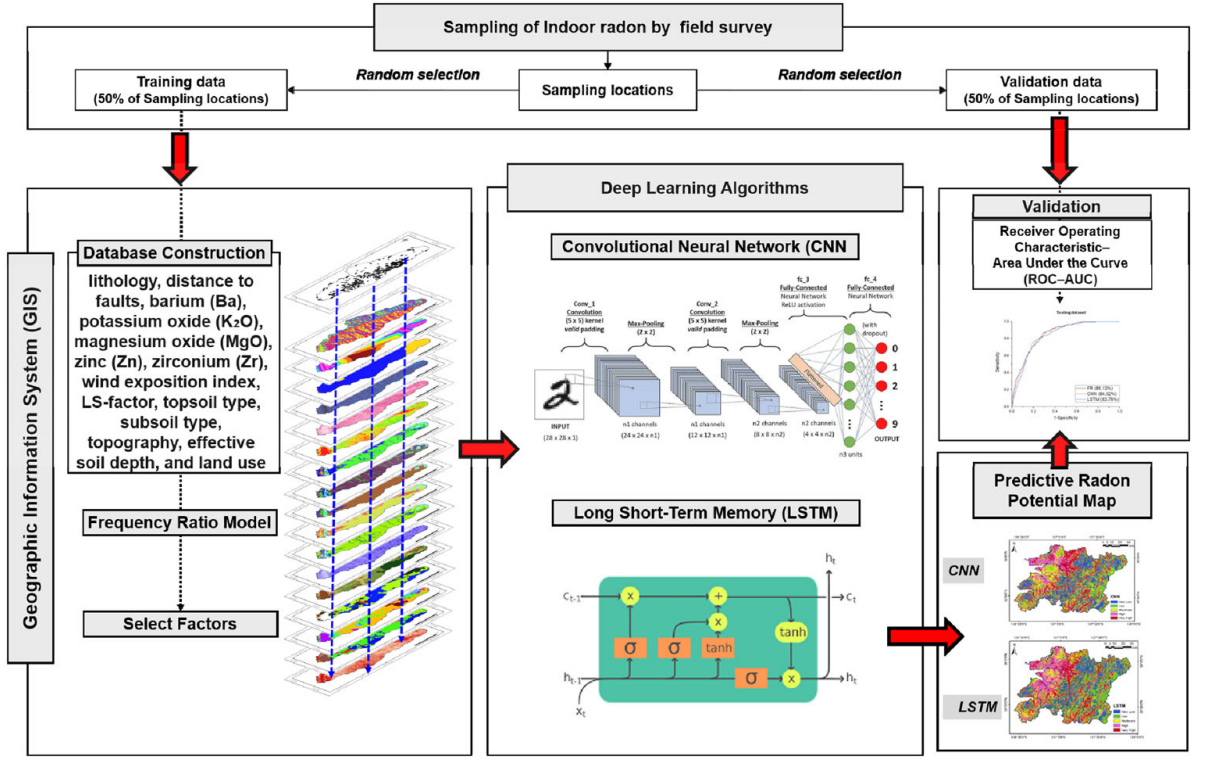
Deep learning-enhanced geospatial modeling for indoor radon mapping in Jeollabuk-do, South Korea
Authors: Saro Lee , Liadira Kusuma Widya , Jungsub Lee , Jongchun Lee , Bo Ram Park , Juhee Yoo , Woojin Lee*
Radon (Rn-222) is a naturally occurring radioactive gas that poses significant lung cancer risks when accumulated indoors, making accurate predictions of its spatial distribution crucial for public health. This study developed a high-resolution radon potential map for Jeollabuk-do, South Korea, using deep learning algorithms. A multivariate spatial database was compiled by integrating geological, geochemical, topographical, soil, and land-use variables. Fourteen input variables, including lithology, distance to faults, barium, potassium oxide, magnesium oxide, zinc, zirconium, wind exposition index, LS-factor (slope length and steepness), surface soil texture, deep soil texture, topography, effective soil thickness, and land use were used. Deep learning models, specifically Convolutional Neural Networks and Long Short-Term Memory networks, were implemented within a GIS framework to generate a predictive radon potential map by modeling relationships between the input variables and indoor radon concentrations, thereby identifying high-risk areas. The resulting radon potential map, produced at a 10 m spatial resolution, was validated using the receiver operating characteristic–area under the curve, achieving an accuracy of approximately 85%. The findings of this study provide a robust foundation for enhancing indoor air quality management and radiation protection strategies.
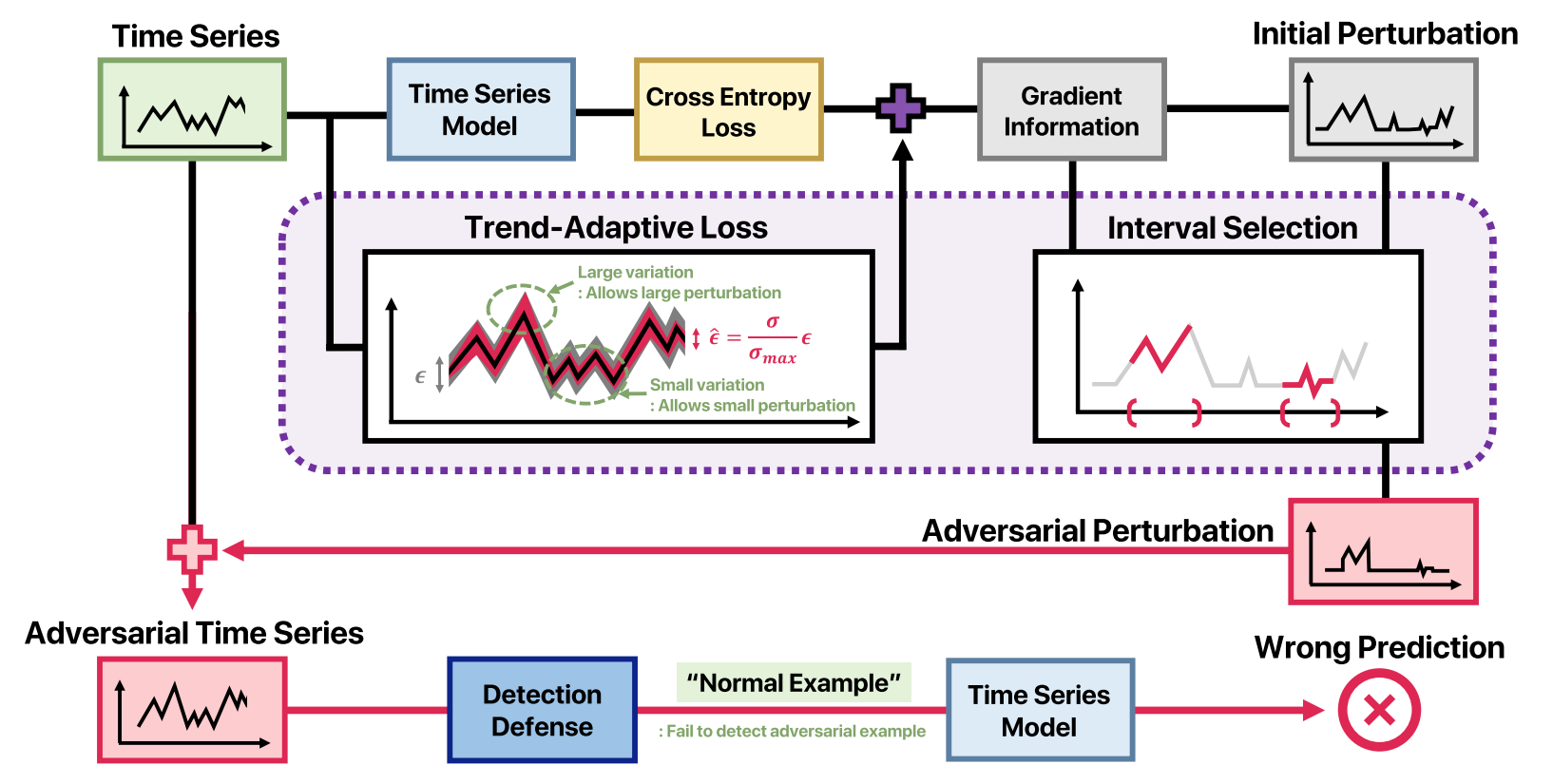
Towards undetectable adversarial attack on time series classification
Authors: Hoki Kim , Yunyoung Lee , Woojin Lee* , Jaewook Lee
Although deep learning models have shown superior performance for time series classification, prior studies have recently discovered that small perturbations can fool various time series models. This vulnerability poses a serious threat that can cause malfunctions in real-world systems, such as Internet-of-Things (IoT) devices and industrial control systems. To defend these systems against adversarial time series, recent studies have proposed a detection method using time series characteristics. In this paper, however, we reveal that this detection-based defense can be easily circumvented. Through an extensive investigation into existing adversarial attacks and generated adversarial time series examples, we discover that they tend to ignore the trends in local areas and add excessive noise to the original examples. Based on the analyses, we propose a new adaptive attack, called trend-adaptive interval attack (TIA), that generates a hardly detectable adversarial time series by adopting trend-adaptive loss and gradient-based interval selection. Our experiments demonstrate that the proposed method successfully maintains the important features of the original time series and deceives diverse time series models without being detected.
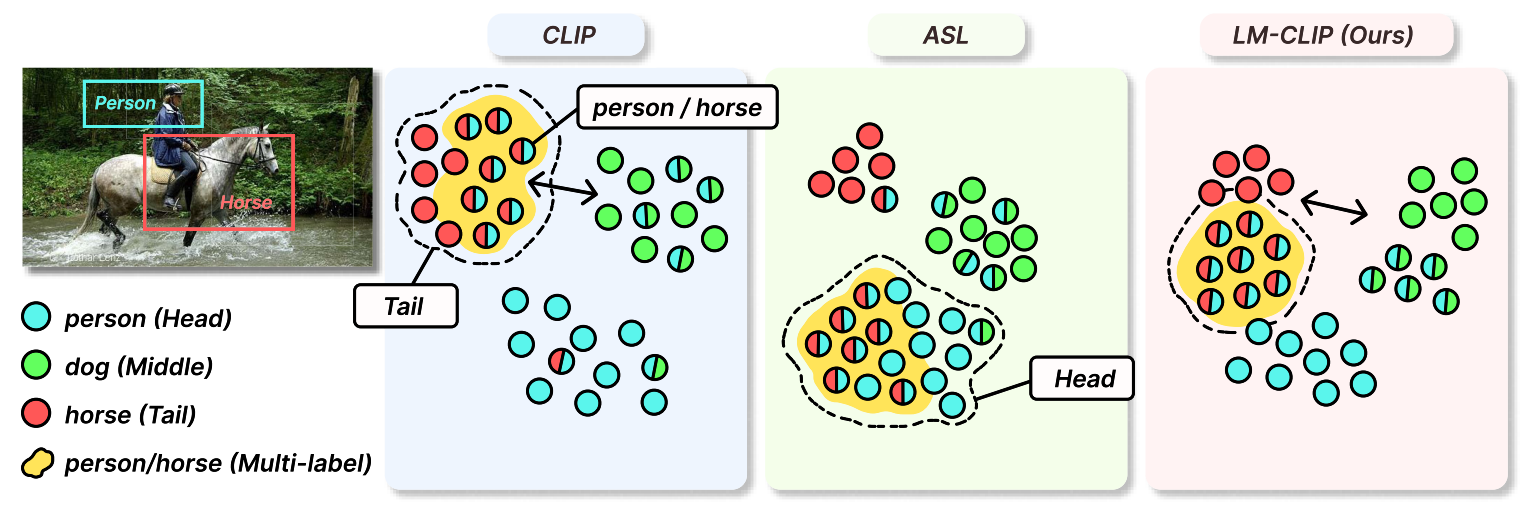
LM-CLIP: Adapting Positive Asymmetric Loss for Long-Tailed Multi-Label Classification
Authors: Christoph Timmermann , Seunghyeon Jung , Miso Kim , Woojin Lee*
Accurate multi-label image classification is essential for real-world applications, especially in scenarios with long-tailed class distributions, where some classes appear frequently while others are rare. This imbalance often leads to biased models that struggle to accurately recognize underrepresented classes. Existing methods either trade off performance between head and tail classes or rely on image captions, limiting adaptability. To address these limitations, we propose LM-CLIP, a novel framework built around a unified loss function. Our Balanced Asymmetric Loss (BAL) extends traditional asymmetric loss by emphasizing the gradients of rare positive samples where the model is uncertain, mitigating bias toward dominant classes. This is complemented by a contrastive loss that pushes negative samples further from the decision boundary, creating a more optimal embedding space even in long-tailed scenarios. These loss functions together ensure balanced performance across all classes. Our framework is built on pre-trained models utilizing textual and visual features from millions of image-text pairs. Furthermore, we incorporate a dynamic sampling strategy that prioritizes rare classes based on their occurrence, which ensures effective training without compromising overall performance. Experiments conducted on VOC-MLT and COCO-MLT benchmarks demonstrate the effectiveness of our approach, achieving +4.66% and +8.14% improvements in mean Average Precision (mAP) over state-of-the-art methods. Our code is publicly available at https://github.com/damilab/lm-clip.
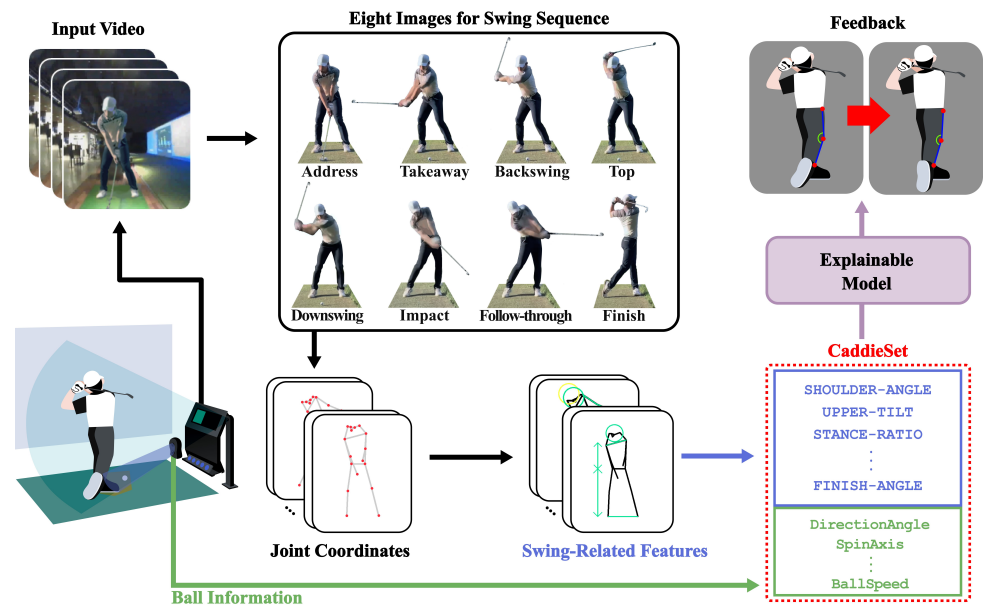
CaddieSet: A Golf Swing Dataset with Human Joint Features and Ball Information
Authors: Seunghyeon Jung , Seoyoung Hong , Jiwoo Jeong , Seungwon Jeong , Jaerim Choi , Hoki Kim , Woojin Lee*
Recent advances in deep learning have led to more studies to enhance golfers' shot precision. However, these existing studies have not quantitatively established the relationship between swing posture and ball trajectory, limiting their ability to provide golfers with the necessary insights for swing improvement. In this paper, we propose a new dataset called CaddieSet, which includes joint information and various ball information from a single shot. CaddieSet extracts joint information from a single swing video by segmenting it into eight swing phases using a computer vision-based approach. Furthermore, based on expert golf domain knowledge, we define 15 key metrics that influence a golf swing, enabling the interpretation of swing outcomes through swing-related features. Through experiments, we demonstrated the feasibility of CaddieSet for predicting ball trajectories using various benchmarks. In particular, we focus on interpretable models among several benchmarks and verify that swing feedback using our joint features is quantitatively consistent with established domain knowledge. This work is expected to offer new insight into golf swing analysis for both academia and the sports industry.
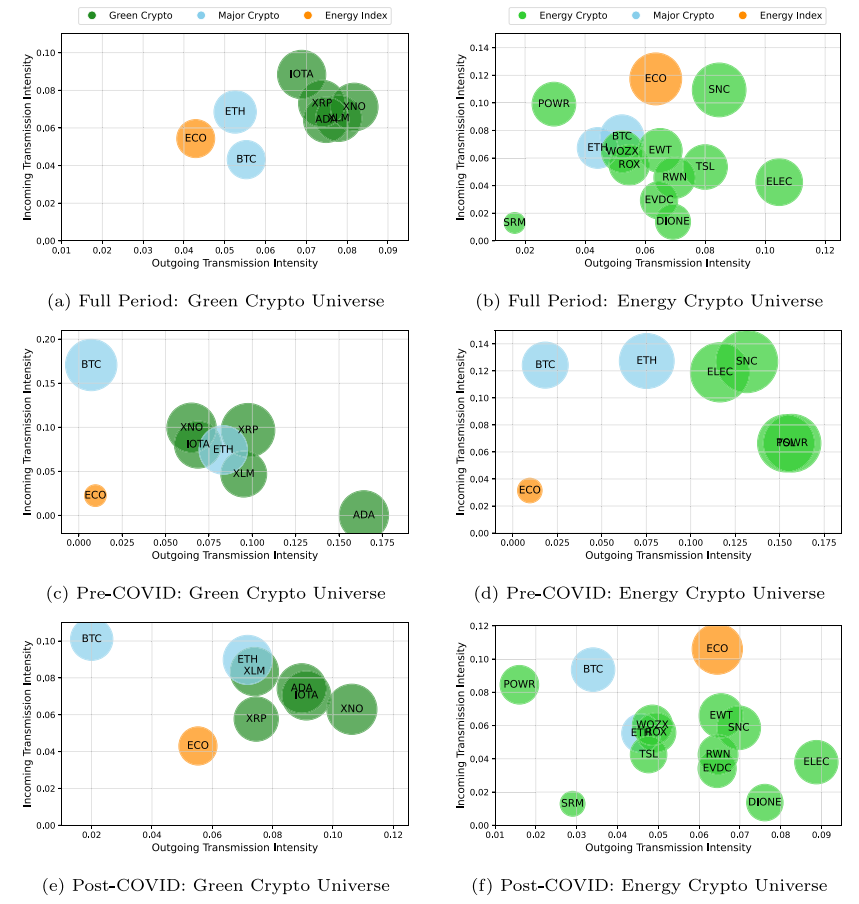
Interconnected dynamics of sustainable cryptocurrencies: Insights from transfer entropy analysis
Authors: Seungju Lee , Jaewook Lee , Woojin Lee*
This study introduces the concept of 'sustainable cryptocurrencies', encompassing green and energy cryptocurrencies, and explores their dynamics alongside diverse assets using transfer entropy based network analysis, including pre- and post-COVID eras. The study reveals that sustainable cryptocurrencies commonly construct a dense transfer entropy network with major cryptocurrencies and the energy index. Meanwhile, they show distinct properties: green cryptocurrencies exhibit significant interconnectedness primarily among themselves, while energy cryptocurrencies show the energy index's emergence as a key component in the post-COVID volatility connectedness network. These insights offer valuable guidance for sustainable investing within cryptocurrency markets.
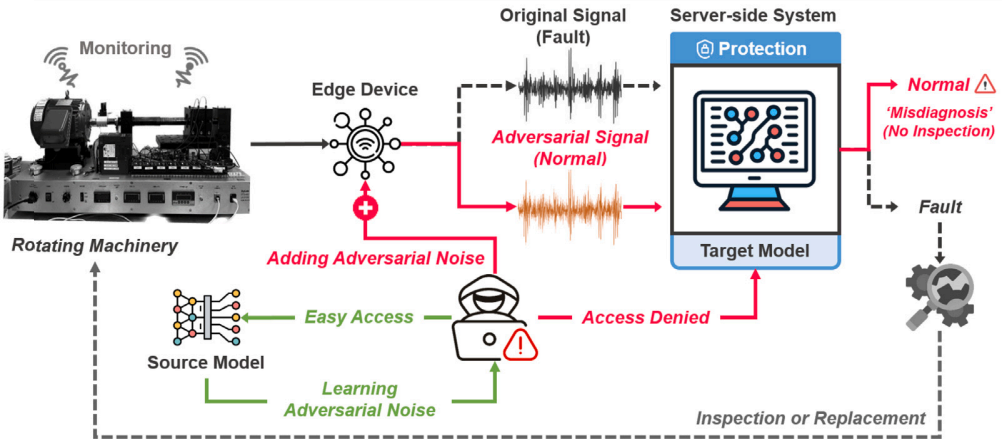
Black-box adversarial examples via frequency distortion against fault diagnosis systems
Authors: Sangho Lee , Hoki Kim , Woojin Lee* , Youngdoo Son
Deep learning has significantly impacted prognostic and health management, but its susceptibility to adversarial attacks raises security risks for fault diagnosis systems. Previous research on the adversarial robustness of these systems is limited by unrealistic assumptions about prior model knowledge, which is often unobtainable in the real world, and by a lack of integration of domain-specific knowledge, particularly frequency information crucial for identifying unique characteristics for machinery states. To address these limitations and enhance robustness assessments, we propose a novel adversarial attack method that exploits frequency distortion. Our approach corrupts both frequency components and waveforms of vibration signals from rotating machinery, enabling a more thorough evaluation of system vulnerability without requiring access to model information. Through extensive experiments on two bearing datasets, including a self-collected dataset, we demonstrate the effectiveness of the proposed method in generating malicious yet imperceptible examples that remarkably degrade model performance, even without access to model information. In realistic attack scenarios for fault diagnosis systems, our approach produces adversarial examples that mimic unique frequency components associated with the deceived machinery states, leading to average performance drops of approximately 13 and 19 percentage points higher than existing methods on the two datasets, respectively. These results reveal potential risks for deep learning models embedded in fault diagnosis systems, highlighting the need for enhanced robustness against adversarial attacks.
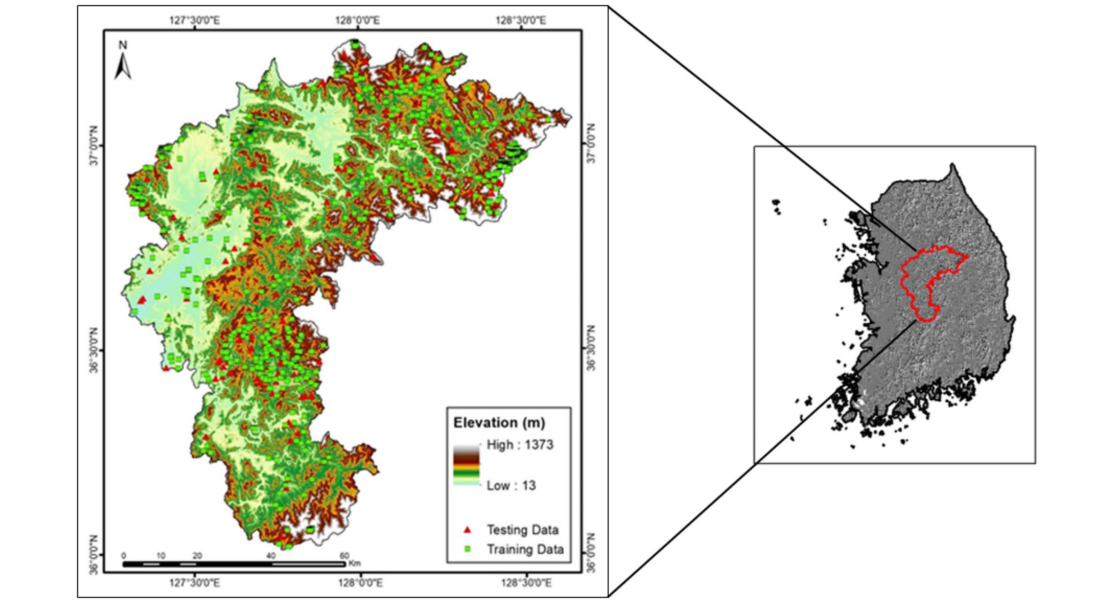
AI-Driven Geospatial Analysis of Indoor Radon Levels: A Case Study in Chungcheongbuk-do, South Korea
Authors: Liadira Kusuma Widya , Fatemeh Rezaie , Jungsub Lee , Jongchun Lee , Bo Ram Park , Juhee Yoo , Woojin Lee* , Saro Lee
Radon is a naturally occurring radioactive gas found in many terrestrial materials, including rocks and soils. Due to the potential health risks linked to persistent exposure to high radon concentrations, it is essential to investigate indoor radon accumulation. This study generated indoor radon index maps for Chungcheongbuk-do, South Korea, selected factors such as lithology, soil depth texture, drainage, material composition, surface texture, soil thickness, calcium oxide and strontium levels, slope, topographic wetness index, wind exposure, valley depth, and the LS factor. These factors were analyzed using frequency ratios (FRs) to assess the influence on indoor radon distribution. The resulting maps were validated with several techniques, including FR, convolutional neural network, long short-term memory, and group method of data handling. The establishment of a geospatial database provided a basis for the integration and analysis of indoor radon levels, along with relevant geological, soil, topographical, and geochemical data. The study calculated the correlations between indoor radon and diverse factors statistically. The indoor radon potential was mapped for Chungcheongbuk-do by applying these techniques, to assess the potential radon distribution. The robustness of the validated model was assessed using the area under the receiver operating curve (AUROC) for both training and testing datasets.
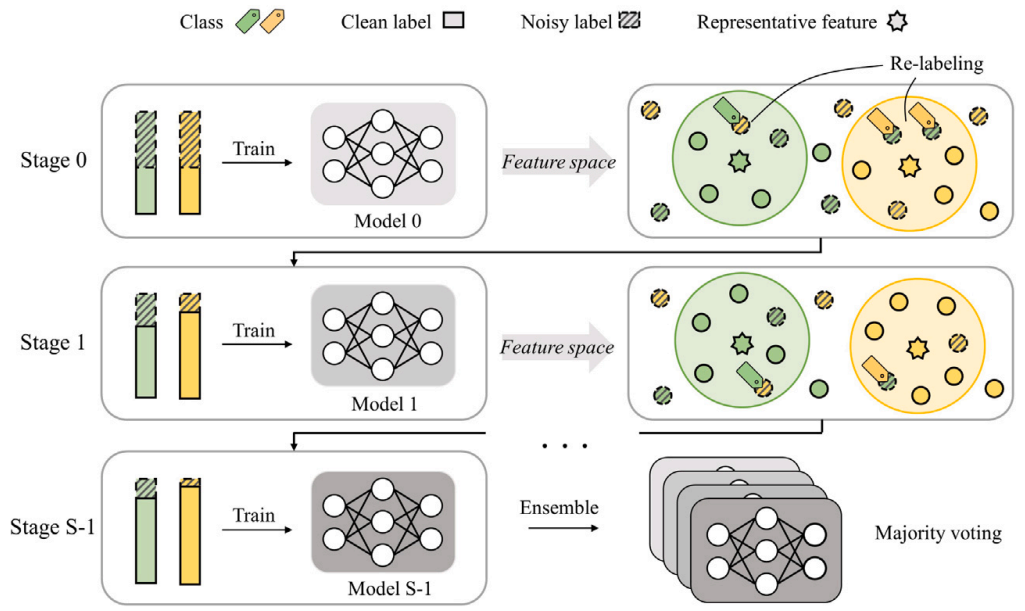
Multi-stage ensemble with refinement for noisy labeled data classification
Authors: Chihyeon Choi , Woojin Lee* , Youngdoo Son
Deep neural networks (DNNs) have made remarkable progress in image classification. However, since DNNs can memorize all the label information in the training dataset due to their excellent feature learning ability, the generalization performance deteriorates when they are trained on the noisy labeled dataset that can be easily found in real-world problems. In this paper, we propose a multi-stage ensemble method with label refinement to build an effective classification model under noisy labels. The proposed method iteratively refines the dataset by re-labeling the samples at the end of each stage, which enables the models trained at each stage to learn different features. By integrating these models, the proposed multi-stage ensemble method exerts powerful generalization performance. Also, we suggest a novel dataset refinement method, demonstrating the effectiveness of a robust function in distinguishing corrupted samples. Experimental results on the benchmark and real-world datasets show that the proposed method outperforms the existing methods on the noisy labeled dataset classification.
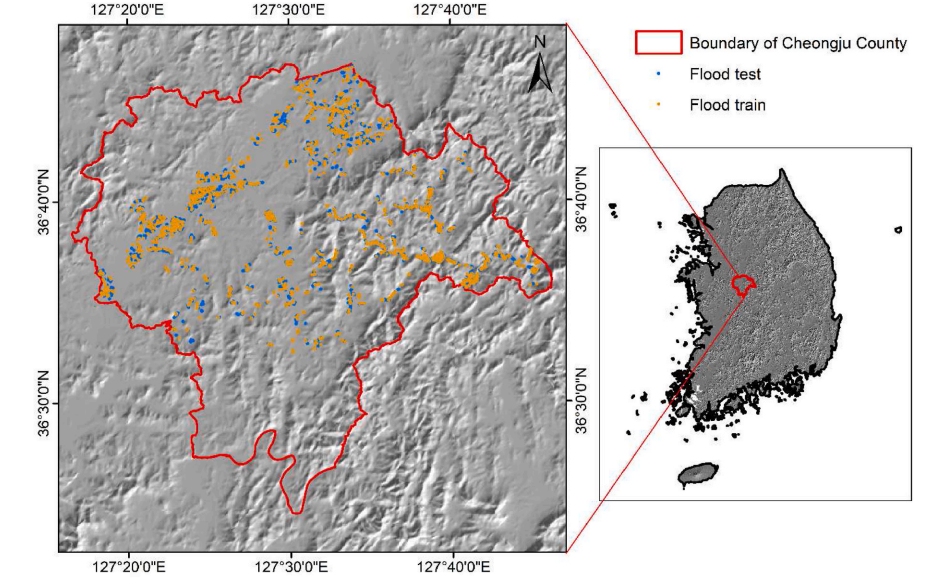
Flood susceptibility mapping of Cheongju, South Korea based on the integration of environmental factors using various machine learning approaches
Authors: Liadira Kusuma Widya , Fatemeh Rezaie , Woojin Lee* , ChangWook Lee , Nurwatik Nurwatik , Saro Lee
Floods are natural occurrences that pose serious risks to human life and the environment, including significant property and infrastructure damage and subsequent socioeconomic challenges. Recent floods in Cheongju County, South Korea have been linked to river overflow. In this study, we created flood susceptibility maps of Cheongju, South Korea using machine learning techniques including support vector regression (SVR), boosted tree (BOOST), and long short-term memory (LSTM) algorithms, based on environmental factors. Potentially influential variables were selected based on flood data gathered through field surveys; these included the slope, aspect, length–slope factor, wind exposition index, terrain wetness index, plan curvature, normalized difference water index, geology, soil drainage, soil depth, soil texture, land use type, and forest density. To improve the robustness of the flood susceptibility model, the most influential factors were identified using the frequency ratio method. Implementing machine learning techniques like SVR and BOOST produced encouraging outcomes, achieving the area under the curve (AUC) of 83.16% and 86.70% for training, and 81.65% and 86.43% for testing, respectively. While, the LSTM algorithm showed superior flood susceptibility mapping performance, with an AUC value of 87.01% for training and 86.91% for testing, demonstrating its robust performance and reliability in accurately assessing flood susceptibility. The results of this study enhance our understanding of flood susceptibility in South Korea and demonstrate the potential of the proposed approach for informing and guiding crucial regional policy decisions, contributing to a more resilient and prepared future.
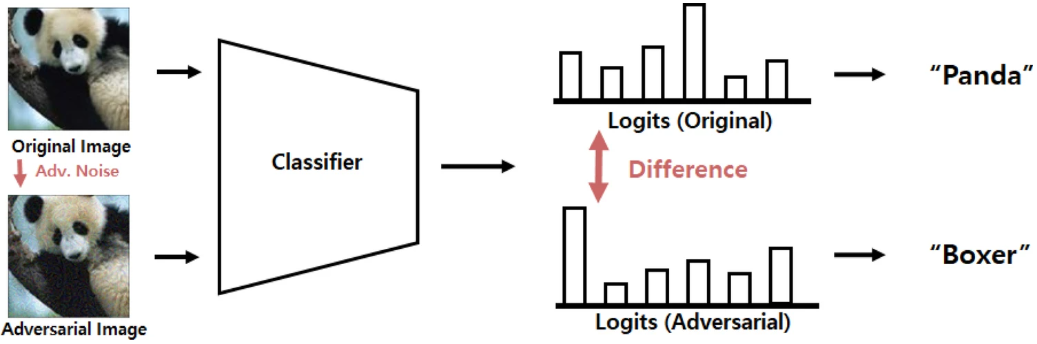
Sliced Wasserstein adversarial training for improving adversarial robustness
Authors: Woojin Lee* , Sungyoon Lee , Hoki Kim , Jaewook Lee
Recently, deep-learning-based models have achieved impressive performance on tasks that were previously considered to be extremely challenging. However, recent works have shown that various deep learning models are susceptible to adversarial data samples. In this paper, we propose the sliced Wasserstein adversarial training method to encourage the logit distributions of clean and adversarial data to be similar to each other. We capture the dissimilarity between two distributions using the Wasserstein metric and then align distributions using an end-to-end training process. We present the theoretical background of the motivation for our study by providing generalization error bounds for adversarial data samples. We performed experiments on three standard datasets and the results demonstrate that our method is more robust against white box attacks compared to previous methods.
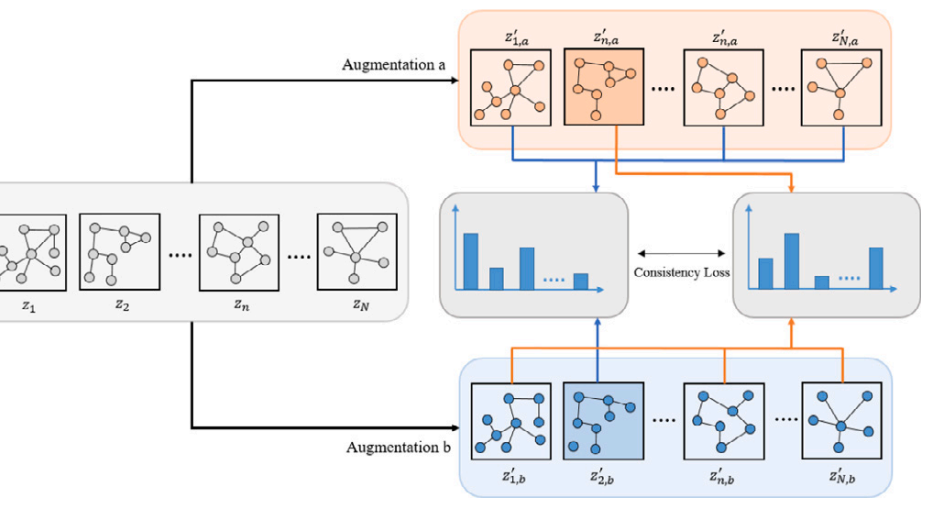
Graph contrastive learning with consistency regularization
Authors: Soohong Lee , Sangho Lee , Jaehwan Lee , Woojin Lee* , Youngdoo Son
Contrastive learning has actively been used for unsupervised graph representation learning owing to its success in computer vision. Most graph contrastive learning methods use instance discrimination. It treats each instance as a distinct class against a query instance as the pretext task. However, such methods inevitably cause a class collision problem because some instances may belong to the same class as the query. Thus, the similarity shared through instances from the same class cannot be reflected in the pre-training stage. To address this problem, we propose graph contrastive learning with consistency regularization (GCCR), which introduces a consistency regularization term to graph contrastive learning. Unlike existing methods, GCCR can obtain a graph representation that reflects intra-class similarity by introducing a consistency regularization term. To verify the effectiveness of the proposed method, we performed extensive experiments and demonstrated that GCCR improved the quality of graph representations for most datasets. Notably, experimental results in various settings show that the proposed method can learn effective graph representations with better robustness against transformations than other state-of-the-art methods.
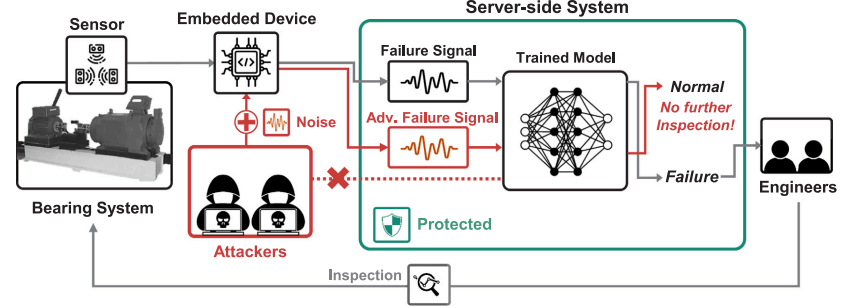
Evaluating practical adversarial robustness of fault diagnosis systems via spectrogram-aware ensemble method
Authors: Hoki Kim , Sangho Lee , Jaewook Lee , Woojin Lee* , Youngdoo Son
While machine learning models have shown superior performance in fault diagnosis systems, researchers have revealed their vulnerability to subtle noises generated by adversarial attacks. Given that this vulnerability can lead to misdiagnosis or unnecessary maintenance, the assessment of the practical robustness of fault diagnosis models is crucial for their deployment and use in real-world scenarios. However, research on the practical adversarial robustness of fault diagnosis models remains limited. In this work, we present a comprehensive analysis on rotating machinery diagnostics and discover that existing attacks often over-estimate the robustness of these models in practical settings. In order to precisely estimate the practical robustness of models, we propose a novel method that unveils the hidden risks of fault diagnosis models by manipulating the spectrum of signal frequencies—an area that has been rarely explored in the domain of adversarial attacks. Our proposed attack, Spectrogram-Aware Ensemble Method (SAEM), the hidden vulnerability of fault diagnosis systems through achieving a higher attack performance in practical black-box settings. Through experiments, we reveal the potential dangers of employing non-robust fault diagnosis models in real-world applications and suggest directions for future research in industrial applications.
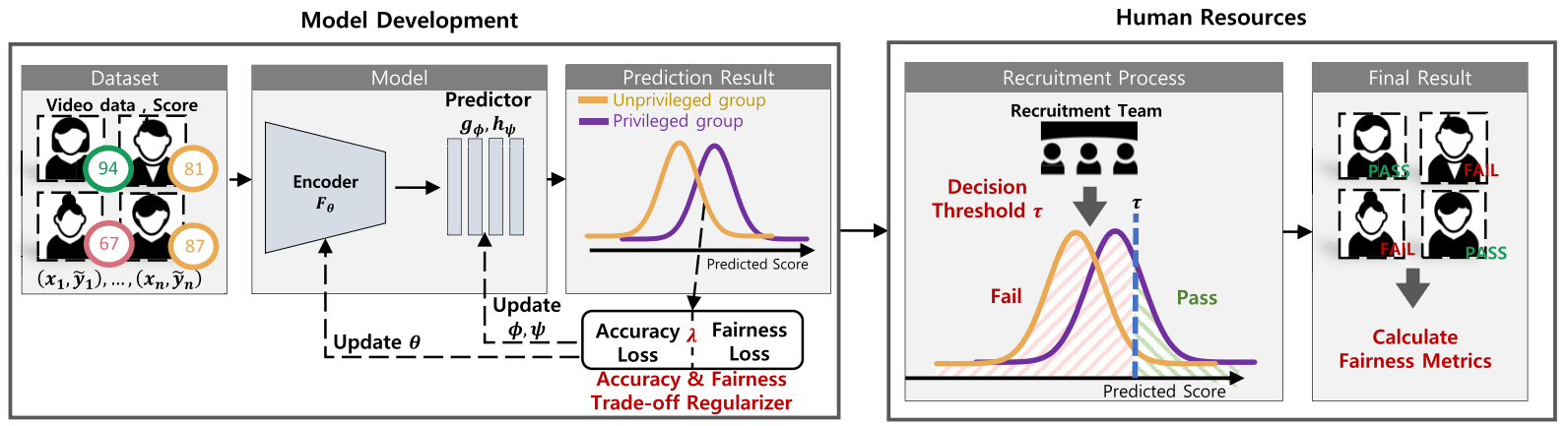
Fairness-Aware Multimodal Learning in Automatic Video Interview Assessment
Authors: Changwoo Kim , Jinho Choi , Jongyeon Yoon , Daehun Yoo , Woojin Lee*
With the ever-growing reliance on Artificial Intelligence (AI) across diverse domains, there is an increasing concern surrounding the possibility of biases and unfairness inherent in AI systems. Fairness problems in automatic interview assessment systems, especially video-based automated interview assessments, have less been addressed despite their prevalence in the recruiting field. In this paper, we propose a method that resolves fairness problems in an automated interview assessment system that uses multimodal data as input. This is mainly done by minimizing the Wasserstein distance between two sensitive groups by introducing a regularization term. Subsequently, we employ a hyperparameter that can control the trade-off between fairness and accuracy. To test our method in various data settings, we suggest a preprocessing method that can manually adjust the underlying degree of unfairness in the training data. Experimental results show that our method presents state-of-the-art results in terms of fairness compared to previous methods.
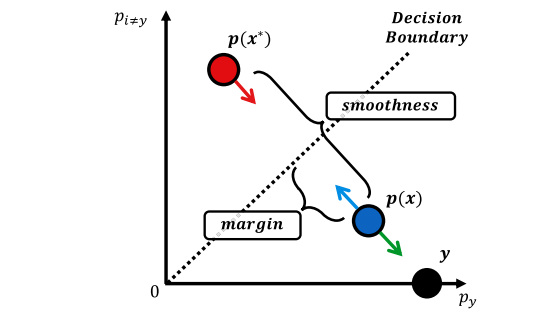
Bridged adversarial training
Authors: Hoki Kim , Woojin Lee* , Sungyoon Lee , Jaewook Lee
Adversarial robustness is considered a required property of deep neural networks. In this study, we discover that adversarially trained models might have significantly different characteristics in terms of margin and smoothness, even though they show similar robustness. Inspired by the observation, we investigate the effect of different regularizers and discover the negative effect of the smoothness regularizer on maximizing the margin. Based on the analyses, we propose a new method called bridged adversarial training that mitigates the negative effect by bridging the gap between clean and adversarial examples. We provide theoretical and empirical evidence that the proposed method provides stable and better robustness, especially for large perturbations.
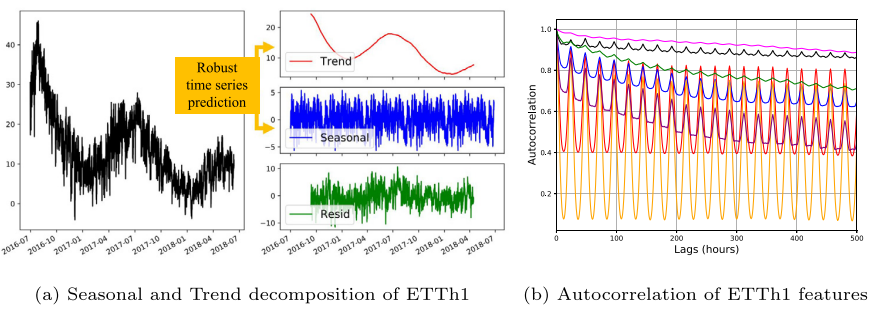
Fast sharpness-aware training for periodic time series classification and forecasting
Authors: Jinseong Park , Hoki Kim , Yujin Choi , Woojin Lee* , Jaewook Lee
Various deep learning architectures have been developed to capture long-term dependencies in time series data, but challenges such as overfitting and computational time still exist. The recently proposed optimization strategy called Sharpness-Aware Minimization (SAM) optimization prevents overfitting by minimizing a perturbed loss within the nearby parameter space. However, SAM requires doubled training time to calculate two gradients per iteration, hindering its practical application in time series modeling such as real-time assessment. In this study, we demonstrate that sharpness-aware training improves generalization performance by capturing trend and seasonal components of time series data. To avoid the computational burden of SAM, we leverage the periodic characteristics of time series data and propose a new fast sharpness-aware training method called Periodic Sharpness-Aware Time series Training (PSATT) that reuses gradient information from past iterations. Empirically, the proposed method achieves both generalization and time efficiency in time series classification and forecasting without requiring additional computations compared to vanilla optimizers.
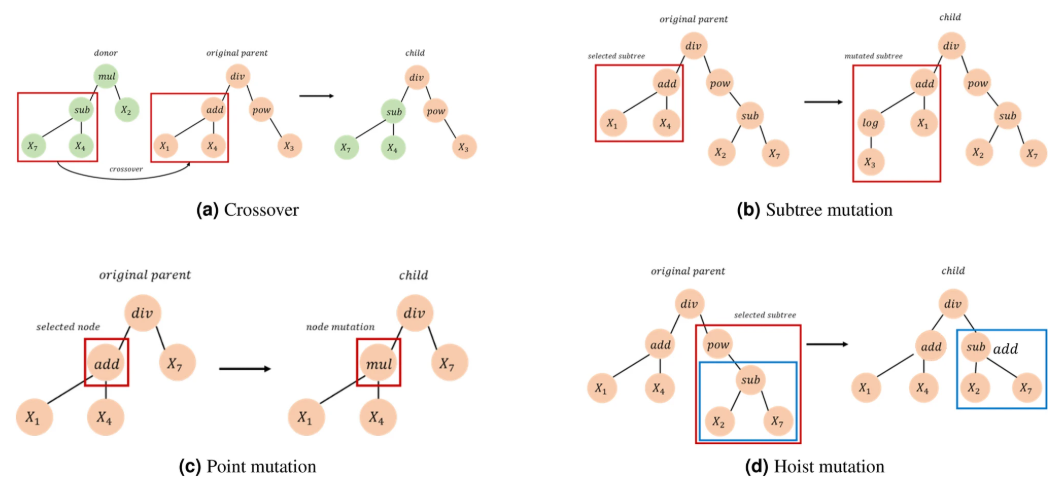
Genetic descriptor search algorithm for predicting hydrogen adsorption free energy of 2D material
Authors: Jaehwan Lee , Seokwon Shin , Jaeho Lee , Young-Kyu Han , Woojin Lee* , Youngdoo Son
Transition metal dichalcogenides (TMDs) have emerged as a promising alternative to noble metals in the field of electrocatalysts for the hydrogen evolution reaction. However, previous attempts using machine learning to predict TMD properties, such as catalytic activity, have been shown to have limitations in their dependence on large amounts of training data and massive computations. Herein, we propose a genetic descriptor search that efficiently identifies a set of descriptors through a genetic algorithm, without requiring intensive calculations. We conducted both quantitative and qualitative experiments on a total of 70 TMDs to predict hydrogen adsorption free energy with the generated descriptors. The results demonstrate that the proposed method significantly outperformed the feature extraction methods that are currently widely used in machine learning applications.
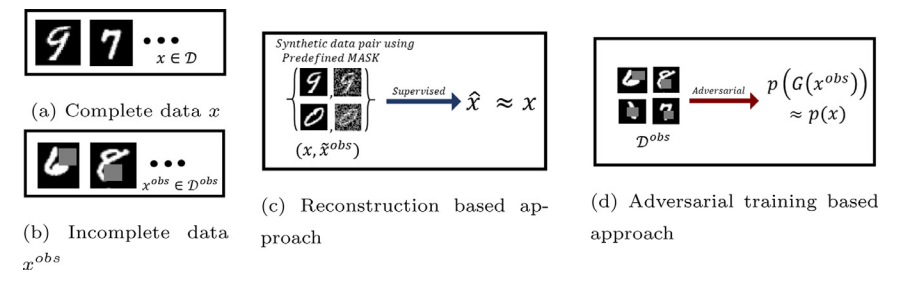
Variational cycle-consistent imputation adversarial networks for general missing patterns
Authors: Woojin Lee* , Sungyoon Lee , Junyoung Byun , Hoki Kim , Jaewook Lee
Imputation of missing data is an important but challenging issue because we do not know the underlying distribution of the missing data. Previous imputation models have addressed this problem by assuming specific kinds of missing distributions. However, in practice, the mechanism of the missing data is unknown, so the most general case of missing pattern needs to be considered for successful imputation. In this paper, we present cycle-consistent imputation adversarial networks to discover the underlying distribution of missing patterns closely under some relaxations. Using adversarial training, our model successfully learns the most general case of missing patterns. Therefore our method can be applied to a wide variety of imputation problems. We empirically evaluated the proposed method with numerical and image data. The result shows that our method yields the state-of-the-art performance quantitatively and qualitatively on standard datasets.
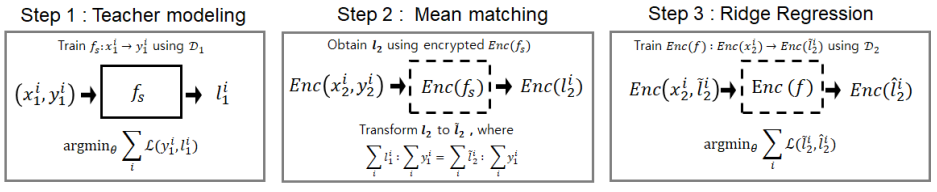
Parameter-free HE-friendly Logistic Regression
Authors: Junyoung Byun , Woojin Lee* , Jaewook Lee
Privacy in machine learning has been widely recognized as an essential ethical and legal issue, because the data used for machine learning may contain sensitive information. Homomorphic encryption has recently attracted attention as a key solution to preserve privacy in machine learning applications. However, current approaches on the training of encrypted machine learning have relied heavily on hyperparameter selection, which should be avoided owing to the extreme difficulty of conducting validation on encrypted data. In this study, we propose an effective privacy-preserving logistic regression method that is free from the approximation of the sigmoid function and hyperparameter selection. In our framework, a logistic regression model can be transformed into the corresponding ridge regression for the logit function. We provide a theoretical background for our framework by suggesting a new generalization error bound on the encrypted data. Experiments on various real-world data show that our framework achieves better classification results while reducing latency by ∼68%, compared to the previous models.
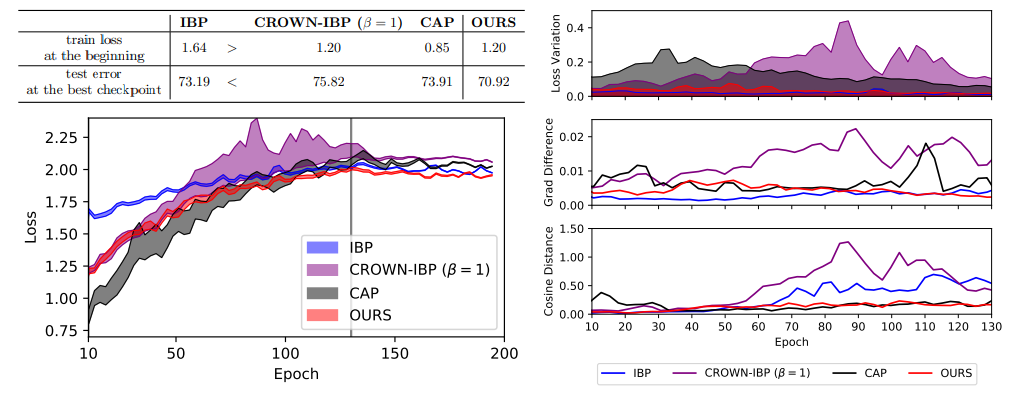
Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples
Authors: Sungyoon Lee , Woojin Lee* , Jinseong Park , Jaewook Lee
We study the problem of training certifiably robust models against adversarial examples. Certifiable training minimizes an upper bound on the worst-case loss over the allowed perturbation, and thus the tightness of the upper bound is an important factor in building certifiably robust models. However, many studies have shown that Interval Bound Propagation (IBP) training uses much looser bounds but outperforms other models that use tighter bounds. We identify another key factor that influences the performance of certifiable training: extit{smoothness of the loss landscape}. We find significant differences in the loss landscapes across many linear relaxation-based methods, and that the current state-of-the-arts method often has a landscape with favorable optimization properties. Moreover, to test the claim, we design a new certifiable training method with the desired properties. With the tightness and the smoothness, the proposed method achieves a decent performance under a wide range of perturbations, while others with only one of the two factors can perform well only for a specific range of perturbations. Our code is available at https://github.com/sungyoon-lee/LossLandscapeMatters.
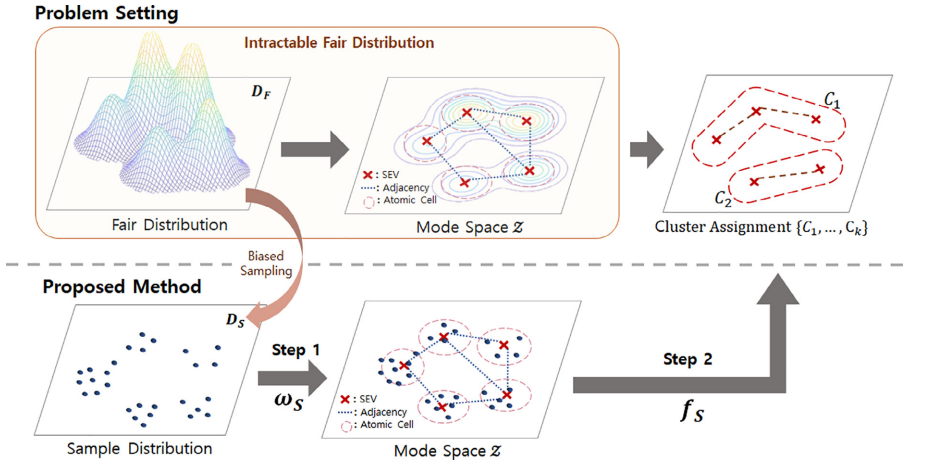
Fair clustering with fair correspondence distribution
Authors: Woojin Lee* , Hyungjin Ko , Junyoung Byun , Taeho Yoon , Jaewook Lee
In recent years, the issue of fairness has become important in the field of machine learning. In clustering problems, fairness is defined in terms of consistency in that the balance ratio of data with different sensitive attribute values remains constant for each cluster. Fairness problems are important in real-world applications, for example, when the recommendation system provides targeted advertisements or job offers based on the clustering result of candidates, the minority group may not get the same level of opportunity as the majority group if the clustering result is unfair. In this study, we propose a novel distribution-based fair clustering approach. Considering a distribution in which the sample is biased by society, we try to find clusters from a fair correspondence distribution. Our method uses the support vector method and a dynamical system to comprehensively divide the entire data space into atomic cells before reassembling them fairly to form the clusters. Theoretical results derive the upper bound of the generalization error of the corresponding clustering function in the fair correspondence distribution when atomic cells are connected fairly, allowing us to present an algorithm to achieve fairness. Experimental results show that our algorithm beneficially increases fairness while reducing computation time for various datasets.
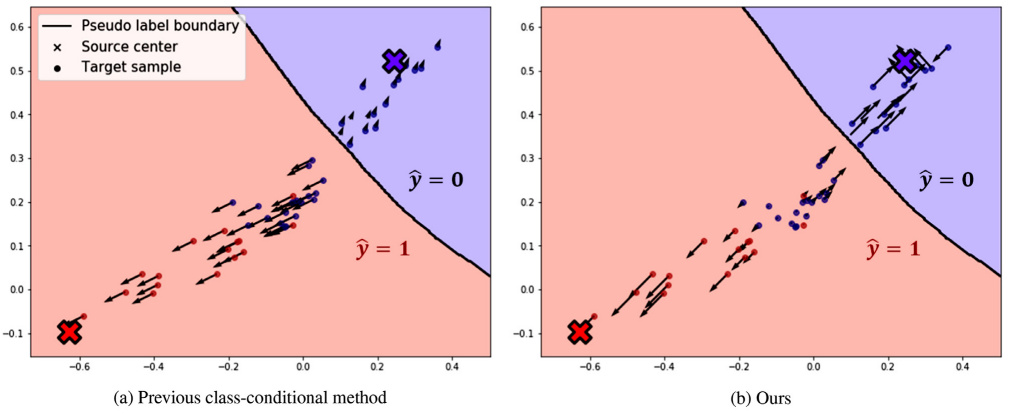
Compact class-conditional domain invariant learning for multi-class domain adaptation
Authors: Woojin Lee* , Hoki Kim , Jaewook Lee
Neural network-based models have recently shown excellent performance in various kinds of tasks. However, a large amount of labeled data is required to train deep networks, and the cost of gathering labeled training data for every kind of domain is prohibitively expensive. Domain adaptation tries to solve this problem by transferring knowledge from labeled source domain data to unlabeled target domain data. Previous research tried to learn domain-invariant features of source and target domains to address this problem, and this approach has been used as a key concept in various methods. However, domain-invariant features do not mean that a classifier trained on source data can be directly applied to target data because it does not guarantee that data distribution of the same classes will be aligned across two domains. In this paper, we present novel generalization upper bounds for domain adaptation that motivates the need for class-conditional domain invariant learning. Based on this theoretical framework, we then propose a class-conditional domain invariant learning method that can learn a feature space in which features in the same class are expected to be mapped nearby. We empirically experimented that our model showed state-of-the-art performance on standard datasets and showed effectiveness by visualization of latent space.
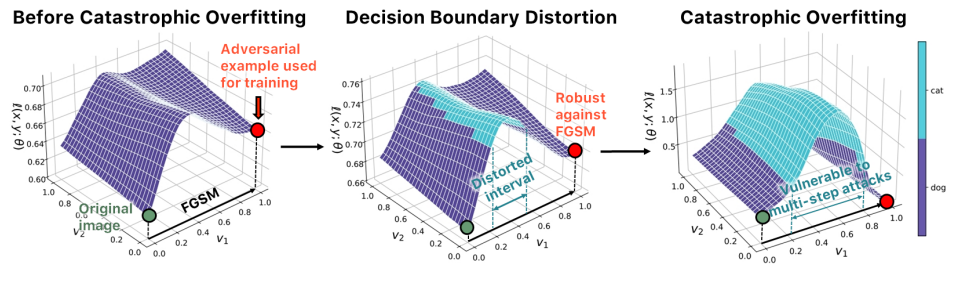
Understanding catastrophic overfitting in single-step adversarial training
Authors: Hoki Kim , Woojin Lee* , Jaewook Lee
Although fast adversarial training has demonstrated both robustness and efficiency, the problem of catastrophic overfitting has been observed. This is a phenomenon in which, during single-step adversarial training, the robust accuracy against projected gradient descent (PGD) suddenly decreases to 0% after a few epochs, whereas the robust accuracy against fast gradient sign method (FGSM) increases to 100%. In this paper, we demonstrate that catastrophic overfitting is very closely related to the characteristic of single-step adversarial training which uses only adversarial examples with the maximum perturbation, and not all adversarial examples in the adversarial direction, which leads to decision boundary distortion and a highly curved loss surface. Based on this observation, we propose a simple method that not only prevents catastrophic overfitting, but also overrides the belief that it is difficult to prevent multi-step adversarial attacks with single-step adversarial training.
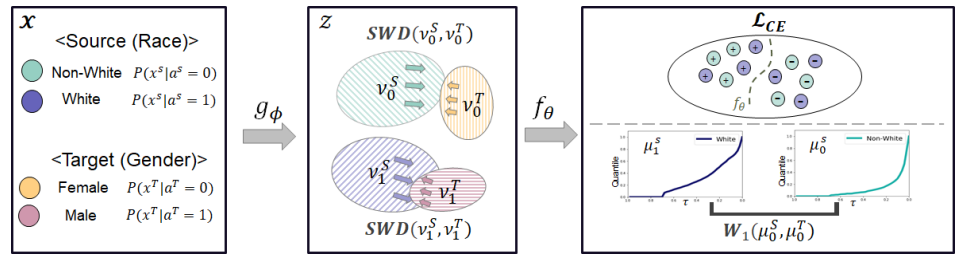
Joint transfer of model knowledge and fairness over domains using wasserstein distance
Authors: Taeho Yoon , Jaewook Lee , Woojin Lee*
Owing to the increasing use of machine learning in our daily lives, the problem of fairness has recently become an important topic in machine learning societies. Recent studies regarding fairness in machine learning have been conducted to attempt to ensure statistical independence between individual model predictions and designated sensitive attributes. However, in reality, cases exist in which the sensitive variables of data used for learning models differ from the data upon which the model is applied. In this paper, we investigate a methodology for developing a fair classification model for data with limited or no labels, by transferring knowledge from another data domain where information is fully available. This is done by controlling the Wasserstein distances between relevant distributions. Subsequently, we obtain a fair model that could be successfully applied to two datasets with different sensitive attributes. We present theoretical results validating that our approach provably transfers both classification performance and fairness over domains. Experimental results show that our method does indeed promote fairness for the target domain, while retaining reasonable classification accuracy, and that it often outperforms comparative models in terms of joint fairness.

Learning of indiscriminate distributions of document embeddings for domain adaptation
Authors: Saerom Park , Woojin Lee* , Jaewook Lee
Natural language processing (NLP) is an important application area in domain adaptation because properties of texts depend on their corpus. However, a textual input is not fundamentally represented as the numerical vector. Many domain adaptation methods for NLP have been developed on the basis of numerical representations of texts instead of textual inputs. Thus, we develop a distributed representation learning method of words and documents for domain adaptation. The developed method addresses the domain separation problem of document embeddings from different domains, that is, the supports of the embeddings are separable across domains and the distributions of the embeddings are discriminated. We propose a new method based on negative sampling. The proposed method learns document embeddings by assuming that a noise distribution is dependent on a domain. The proposed method moves a document embedding close to the embeddings of the important words in the document and keeps the embedding away from the word embeddings that occur frequently in both domains. For Amazon reviews, we verified that the proposed method outperformed other representation methods in terms of indiscriminability of the distributions of the document embeddings through experiments such as visualizing them and calculating a proxy A-distance measure. We also performed sentiment classification tasks to validate the effectiveness of document embeddings. The proposed method achieved consistently better results than other methods. In addition, we applied the learned document embeddings to the domain adversarial neural network method, which is a popular deep learning-based domain adaptation model. The proposed method obtained not only better performance on most datasets but also more stable convergences for all datasets than the other methods. Therefore, the proposed method are applicable to other domain adaptation methods for NLP using numerical representations of documents or words.
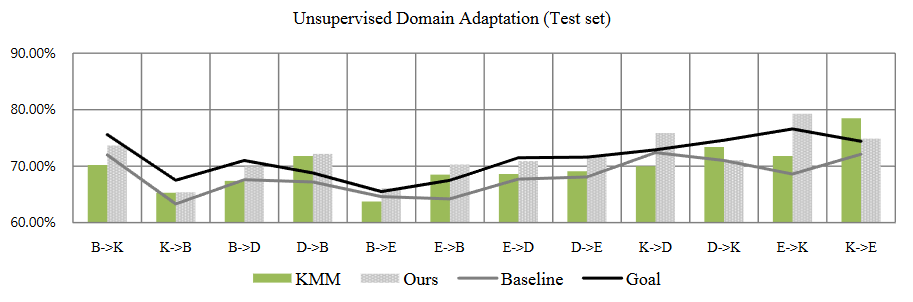
Instance weighting domain adaptation using distance kernel
Authors: Woojin Lee* , Jaewook Lee , Saerom Park
Domain adaptation methods aims to improve the accuracy of the target predictive classifier while using the patterns from a related source domain that has large number of labeled data. In this paper, we introduce new kernel weight domain adaptation method based on smoothness assumption of classifier. We propose new simple and intuitive method that can improve the learning of target data by adding distance kernel based cross entropy term in loss function. Distance kernel refers to a matrix which denotes distance of each instances in source and target domain. We efficiently reduced the computational cost by using the stochastic gradient descent method. We evaluated the proposed method by using synthetic data and cross domain sentiment analysis tasks of Amazon reviews in four domains. Our empirical results showed improvements in all 12 domain adaptation experiments.
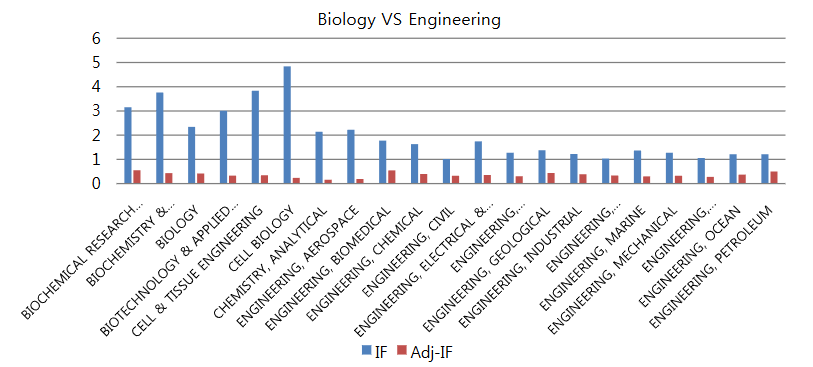
Adjusted Impact Factor by using F min Search Algorithm
Authors: Woojin Lee* , Junghoon Hah , Namhyoung Kim
Assessing research quality is a crucial task for research institutions. Impact Factor has been widely used as a journal evaluation metric. It also has been used as an evaluation metric for researcher’s research ability. However, assessing research quality using Impact Factor can raises various problems, especially when evaluating researchers from different research fields at the same time. For instance, lower Impact Factors are given to traditional engineering and social sciences than those given to general sciences and biology. To solve these problems, adjusted Impact Factor has been proposed. They have the effect of normalizing Impact Factors in different subject categories. However, these revised Impact Factors cause errors in relative rankings among journals. By using linearly combined 11 revised Impact Factor, we find the optimal combination to reduce the error rate and give a solution to weak point of current Impact Factor.
Information-based boundary equilibrium generative adversarial networks with interpretable representation learning
Authors: Junghoon Hah , Woojin Lee* , Jaewook Lee , Saerom Park
This paper describes a new image generation algorithm based on generative adversarial network. With an information-theoretic extension to the autoencoder-based discriminator, this new algorithm is able to learn interpretable representations from the input images. Our model not only adversarially minimizes the Wasserstein distance-based losses of the discriminator and generator but also maximizes the mutual information between small subset of the latent variables and the observation. We also train our model with proportional control theory to keep the equilibrium between the discriminator and the generator balanced, and as a result, our generative adversarial network can mitigate the convergence problem. Through the experiments on real images, we validate our proposed method, which can manipulate the generated images as desired by controlling the latent codes of input variables. In addition, the visual qualities of produced images are effectively maintained, and the model can stably converge to the equilibrium. However, our model has a difficulty in learning disentangling factors because our model does not regularize the independence between the interpretable factors. Therefore, in the future, we will develop a generative model that can learn disentangling factors.
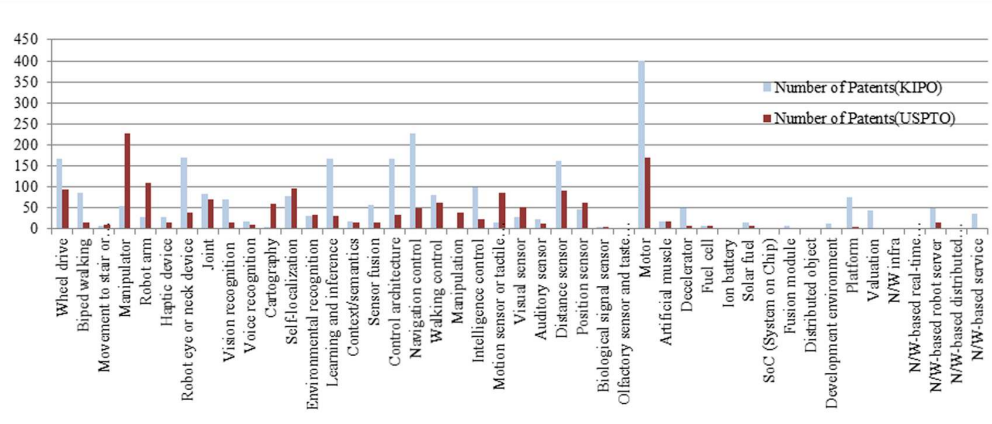
Patent network analysis and quadratic assignment procedures to identify the convergence of robot technologies
Authors: Woojin Lee* , Won Kyung Lee , Soyoung Sohn
Because of the remarkable developments in robotics in recent years, technological convergence has been active in this area. We focused on finding patterns of convergence within robot technology using network analysis of patents in both the USPTO and KIPO. To identify the variables that affect convergence, we used quadratic assignment procedures (QAP). From our analysis, we observed the patent network ecology related to convergence and found technologies that have great potential to converge with other robotics technologies. The results of our study are expected to contribute to setting up convergence based R&D policies for robotics, which can lead new innovation.
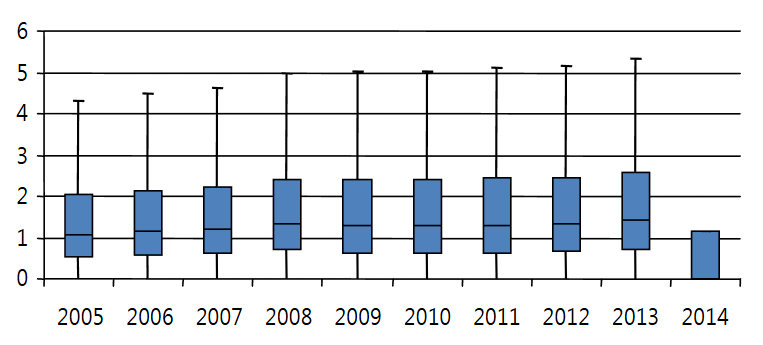
A Novel journal evaluation metric that adjusts the impact factors across different subject categories
Authors: Sujin Pyo , Woojin Lee* , Jaewook Lee
During the last two decades, impact factor has been widely used as a journal evaluation metric that differentiates the influence of a specific journal compared with other journals. However, impact factor does not provide a reliable metric between journals in different subject categories. For example, higher impact factors are given to biology and general sciences than those assigned to other traditional engineering and social sciences. This study initially analyzes the trend of the time series of the impact factors of the journals listed in Journal Citation Reports during the last decade. This study then proposes new journal evaluation metrics that adjust the impact factors across different subject categories. The proposed metrics possibly provides a consistent measure to mitigate the differences in impact factors among subject categories. On the basis of experimental results, we recommend the most reliable and appropriate metric to evaluate journals that are less dependent on the characteristics of subject categories.
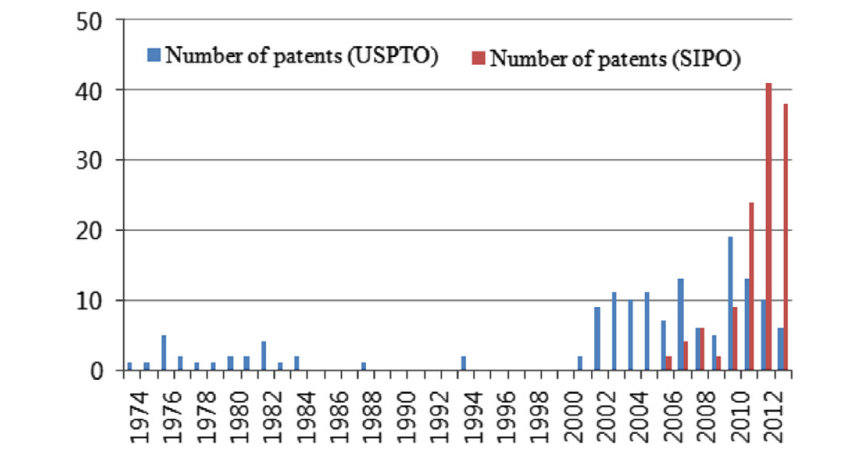
Patent analysis to identify shale gas development in China and the United States
Authors: Woojin Lee* , Soyoung Sohn
Shale gas has become an increasingly important form of hydrocarbon energy, and related technologies reflect the geographical characteristics of the countries where the gas is extracted and stored. The United States (U.S.) produces most of the world’s shale gas, while China has the world’s largest shale gas reserves. In this research, we focused on identifying the trends in shale-gas related technologies registered to the United States Patent and Trademark Office (USPTO) and to the State Intellectual Property Office of the People’s Republic of China (SIPO) respectively. To cluster shale-gas related technologies, we text-mined the abstracts of patent specifications. It was found that in the U.S., the key advanced technologies were related to hydraulic fracturing, horizontal drilling, and slick water areas, whereas China had a focus on proppants. The results of our study are expected to assist energy experts in designing energy policies related to technology importation.